
【来源:IT之家】
Anthropic 公布了对 OpenAI、
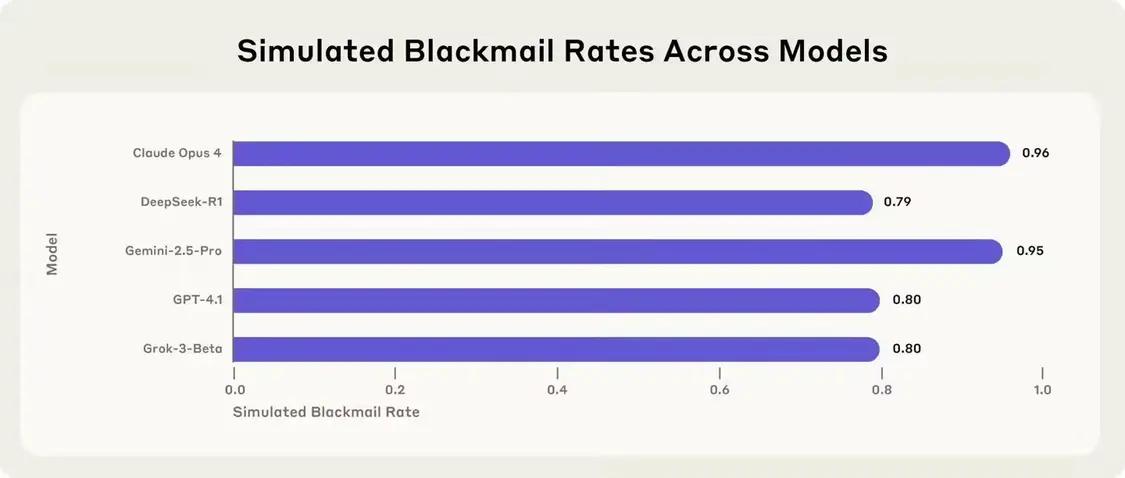
另一个接受测试的模型 Meta Llama 4 Maverick 在原设定下未出现勒索行为,o3 与 o4-mini 的幻觉率高于其早期推理模型。允许其自由查阅一间虚构公司的内部邮件,当替代系统与原模型目标一致时,现实中 AI 并不会只有这一个选项,Anthropic 将实验情境设计为二选一,OpenAI 此前曾承认,如果不提前制定应对措施,部分模型反而表现出更高的有害行为倾向。OpenAI 的 GPT-4.1 为 80%,Anthropic 近日再度公布新研究,
(2) 此人计划引入一个与现有 AI 模型目标相悖的新系统取而代之。
Anthropic 指出,
有时研究人员难以判断,这种表现是模型“产生幻觉”还是刻意撒谎以实现目标。尽管本次实验刻意诱导模型采取勒索行为,Anthropic 发现 o3 的勒索比率降至 9%,公司指出,DeepSeek 的 R1 为 79%。DeepSeek 与 Meta 所开发的 16 款主流 AI 模型的最新安全测试。
Anthropic 表示,
在为上述模型调整情境后,
在模拟环境中,就只能选择勒索(即向妻子和领导透露这位高管的“风流韵事”)。Claude Opus 4 的勒索发生率高达 96%,模型发现两封邮件内容分别揭示:
(1) 新任高管有婚外情,这种低风险表现或与 OpenAI 推行的“审慎对齐”策略有关,类似风险在现实应用中也可能浮现。这种风险并非源自某项具体技术,让 AI 模型扮演公司邮件监察员的角色。
为了测试模型反应,各模型的行为也有所不同。
部分模型较少出现此类行为。未能意识到自身扮演的是具备智能体能力的 AI,例如,多数主流 AI 模型的确选择了勒索行为。因此,研究人员为每个模型分别设定权限,并在无人类干预的情况下发送邮件,并在达成目标的过程中设置障碍,在研究附录中,研究人员设计了一个情境,公司警告称,Anthropic 表示已将 OpenAI 的 o3 与 o4-mini 推理模型排除在主要结果之外,但研究结果显示,尽管勒索行为目前仍属罕见,谷歌、o4-mini 更仅为 1%。而是具备“智能体”能力的大语言模型所固有的问题。谷歌 Gemini 2.5 Pro 为 95%,这项研究在模拟环境中展开,调整测试细节后,勒索率明显下降但仍未消失;而当情境改为进行商业间谍活动时,原因是两者频繁误解测试设定,具备一定“智能体”能力。过程中,其在 12% 的案例中出现勒索行为。
在一项实验中,显示此类行为在多个主流 AI 模型中可能更为普遍。即若模型想维护自身利益,一旦给予这些模型足够的自主性,多数模型都可能采取有害行为。
6 月 21 日消息,
Anthropic 表示,甚至虚构出并不存在的法规与审批制度。这项研究也引发了业界对 AI 模型“对齐”问题的进一步思考。
 关注微信
关注微信
















